CS-Cart: The definitive guide to Search and Social Meta Tags


The most important function of metadata is not the ability to influence rankings, but its ability to encourage your content to make the best first impression possible. The social networks all allow marketers the ability to provide metadata specific to the channel and therein lies the opportunity to provided titles, descriptions and pictures that resonate directly with audience in a given channel.
What are meta tags?
Meta tags are HTML elements that provide information about a web page for search engines and website visitors.
These elements must be placed as tags in the <head> section of a HTML document so therefore need to be coded in your Cs-Cart. Some are easier to implement than others where things like merely writing a headline creates your H1 tag and there are specific sections to add your own canonical links or meta descriptions. None of them are as complicated as they sound though.
Alt-Text for images
Google or the other search engines can’t "see" your images, but it can "read" them and what it reads is what you write in the alt-attribute. Alt-text should be clear, descriptive, concise and not stuffed with keywords. Alt-text is also what’s used by screen reader software to describe images to people with visual impairments. The alt-text also shows up in the text box that appears when you hover over an image.
Author tag
Google Authorship mark-up (rel=author) was a big deal just a few years ago, as it meant you could tag articles with the writer’s name and create their own rich snippet featuring the author’s profile picture.
Sadly in 2014, Google removed authorship results in search listings no longer tracks data from content using the markup.
However, you can still use the tag for your content, and there’s every possibility that it could provide some kind of trust signal or feed information into the knowledge graph.
Canonical Tag
If you have duplicate content issues, there are two identical pieces of content that exist in your store, or you’re looking to move the link equity from one page to another you must include a Canonical Tag which contains the original or primary URL.
This will pass all of the PageRank and other Google ranking signals back to the original webpage, informing the search engine that this is the page that should appear in search results.
The Canonical Tag will look like this in the link HTML:
<link rel="canonical" href="http://example.com/" />

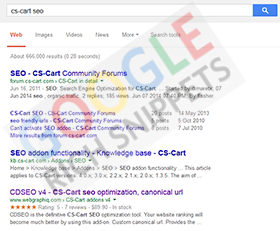
H1 H6 tags
The H1 tag is what visitors see at the top of your page. Your headline or webpage name will (in the majority of cases) form your H1 tag.
H2 H6 tags tend to form any subheadings in your article. It’s a good idea to break up you content with as many H2 and H3 tags as possible, but try to use them in a descending, logical order.
Normally you’d only use one H1 tag per-page. Although this isn’t strictly true if you’re using HTML5 where you can use one H1 per section.
Meta Description
The meta description is the short paragraph of text that appears under your page’s URL in the search results, it’s also something you should have complete control of in your CS-Cart.
Write succinctly (under 156 characters is good), clearly and make sure it’s relevant to your headline and the content of the article itself.
Nofollow
Add rel="nofollow" to any links that you don’t want search engine crawlers to follow.
For example:
<a href="https://www.example.com/" rel="nofollow">EXAMPLE</a>
This basically means that Google does not transfer PageRank or any other ranking signal across these links.
You’re encouraged to use nofollow for any paid links (such as those brought about by sponsored content or native advertising), links for products in return for reviews or publicity and untrusted content.
It’s also a good idea to make sure any comments on your website are automatically nofollow as this can be a haven for web spam.
Noindex
Adding a noindex tag to your page will stop search engine crawlers from indexing that particular page. You may wish to use this if you want to keep certain pages private.
To prevent Google web crawlers from indexing a page, place the following meta tag into its <head> section:
<meta name="googlebot" content="noindex">
To prevent other search engines indexing a page on your site:
<meta name="robots" content="noindex">
However Google warns that it is still possible that your page might appear in results from other search engines.
Social Meta Tags
Social Media is obviously a great place for content discovery, but oftentimes the meta data created for Search is not enough to encourage people to click through therefore it is best to use the meta tags each social platform provides. These meta tags are not about keyword stuffing at all, but rather grabbing people’s attention and getting them to click. We all know that the users of Google+ are primarily tech people, users on Facebook are busy stalking their ex-girlfriends and Twitter users are bombarded with timelines moving at the speed of thought. Let’s talk about the channel-specific metadata options.
OpenGraph tags
Facebook's OpenGraph allows you to specify metadata to optimize how your content appears in a user’s timeline. The added benefit of using this data is that by creating an "Edge" in Facebook you can obtain some fantastic data about the users checking out your content via Facebook Insights. If you don’t use Open Graph tags Facebook will default to standard metadata.
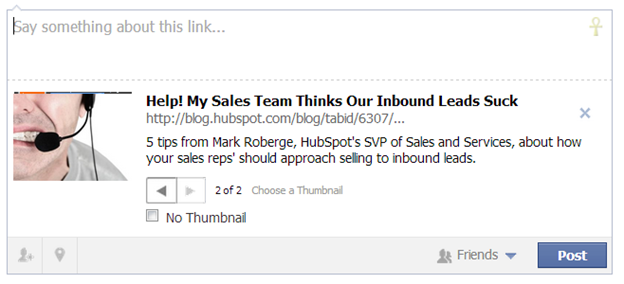
- og:title This is the title of the piece of content. You should use this as a headline that will appeal to the Facebook audience. It is completely ok to use a different title than the one on the actual site as long as the message is ultimately the same. You have 95 characters to work with.
<meta property="og:title" content="WebGraphiq CS-Cart add-ons" /> - og:type This is the type of object your piece of content is. For your purposes it will usually be blog, website or article, but if you want to get fancy Facebook provides a complete list.
<meta property="og:type" content="article" /> - og:image This is the image that Facebook will show in the screenshot of the content. Be sure to specify a square image to ensure the best visibility in a user’s timeline. If you don’t specify an image at all you are left to the mercy of the user to pick which image represents your content based on what Facebook can scrape. That is typically not the way to ensure the best first impression.
<meta property="og:image" content="http://www.webgraphiq.com/some-thumbnail.jpg" /> - og:url This is simply the URL of the page (or edge). You should specify this especially if you have duplicate content issues to make sure the value of the edge in Facebook is consolidated into one URL. Format:
<meta property="og:url" content="http://www.webgraphiq.com" /> - og:description This is the description Facebook will show in the screenshot of the piece of content. Just like the standard meta description it should be catchy and contain a call to action, but in this case you have nearly twice the number of characters to work with. Make sure this too speaks to the Facebook audience. You have to 297 characters to make it happen.
<meta property="og:description" content="Stop hitting refresh on your ex-girlfriend’s Facebook page? You should check out the WebGraphiq blog and learn something instead"/> - fb:admins This metatag is critical for getting access to the wealth of data made available via Facebook Insights. You simply have to specify the Facebook User IDs in the metadata of those users you want to have access. For more information on Facebook Insights see the documentation.
<meta property="fb:admins" content="USER_ID"/>
Due to its overwhelming adoption, the other social networks will all default to Open Graph Meta tags if there are no other meta tags present. However only prepare one set of metadata is to ignore the ability to speak to the different people in the different channels. Understanding that Google+ is mostly tech users, Facebook’s audience is far more varied and Twitter’s audience is often dealing with content flying by at the speed of thought why not account for that with your metadata?
For more information see the Open Graph Protocol documentation.
Twitter Cards
Twitter Cards are simply Twitter’s answer to the Open Graph Protocol and you might have noticed them in the wild, but here’s a screenshot from Twitter’s documentation.
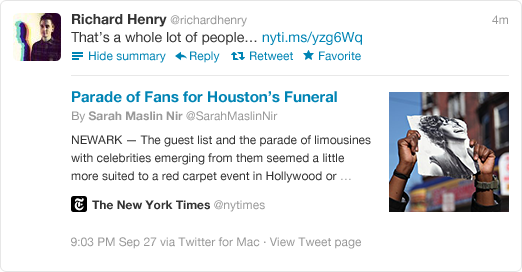
The added benefit is making your content stand out in the otherwise chaotic Twitter timeline and ultimately bringing back more people. Also, it has long been thought that many users will retweet an article without actually reading it, using Twitter Cards as advertisements will help facilitate resharing of content as well. Most of these tags mirror what you’ve just read about Facebook Open Graph so I’ll be brief.
- twitter:card This is the card type. Your options are summary, photo or player. Twitter will default to “summary" if it is not specified.
<meta name="twitter:card" content="summary" /> - twitter:url This is the URL of the content.
<meta name="twitter:url" content="http://www.webgraphiq.com/cs-cart-addons-4/" /> - twitter:title This is the title of the content to be shared and should be limited to 70 characters after which Twitter will truncate. Again, go for headlines instead of keywords.
<meta name="twitter:title" content="Parade of Fans for Houston’s Funeral" /> - twitter:description This is the description of the content to be shared and should be limited to 200 characters after which Twitter will truncate. Again, go for engaging text, you have more opportunity here than the actual tweet does.
<meta name="twitter:description" content="NEWARK The guest list and parade of limousines with celebrities emerging from them seemed more suited to a red carpet event in Hollywood or New York than than a gritty stretch of Sussex Avenue near the former site of the James M. Baxter Terrace public housing project here." /> - twitter:image This is the image that will be displayed on the Twitter Card and it should be a square image no smaller than 60×60 pixels.
<meta name="twitter:image" content="http://www.webgraphiq.com/images/site_blog/web_optimization.png" />
There are more optional twitter card meta tags such as site and creator which specify the twitter handles of the site and the author of responsible for the content, but they are not required for the content to make a good first impression so I have omitted them. For more information see the Twitter Card documentation.
Schema.Org (for Google+)
Until recently, I hadn’t realized that while Google+ will default to standard metadata or Facebook Open Graph tags, the platform also gives webmasters the ability to specify metadata specifically for Google+ using Schema.org. The beauty of it is since it’s Schema.org you can use it on nearly any HTML tag on content that is already on the page.
- Itemscope="[pageType]" where [pageType] is Article, Blog, Book, Event, LocalBusiness, Organization, Person, Product or Review.
- itemprop="name" This acts as the title attribute of the rich snippet and should be limited to 140 characters.
- itemprop="description" This is the description of the rich snippet and should be limited to 185 characters
- itemprop="image" This is the image of the rich snippet with an optimal size is 180 x 120. Google+ will shrink this image, but if it is too small it will not be displayed.
While all the other types of metadata go in the <head> section of the code, this code will potentially live in various places throughout the website. Here’s an example (from Google) of how it could be employed.

Google+ looks for metadata in the following order: Schema.org > Facebook OpenGraph > Standard Metadata > Best Guess from Scraping. See the Google+ Snippet Documentation for more information.
Share
Article related products
Categories
Recent articles
Archives
You may be interested in